Agentic AI in Hardware Design Verification
Exploring the use of multi-agent AI systems to autonomously close coverage gaps in hardware verification, leveraging LLMs and LangGraph for orchestration.
arXiv: Understanding Inference-Time Token Allocation and Coverage Limits in Agentic Hardware Verification
Chip verification is where schedules go to die. A design can be architecturally brilliant, pass every code review, and still spend months stuck in a loop of testbench refinement, coverage analysis, and "why isn't this branch getting hit?" According to the 2024 Wilson Research Group study, 60-70% of engineering effort in chip projects goes to verification, and only 14% of ASIC/SoC projects achieved first-silicon success last year. The bottleneck isn't writing tests. It's closing coverage.
We built CovAgent to do this autonomously. It's an agentic framework that reads a design specification, generates SystemVerilog testbenches, runs simulations, parses coverage reports, and iterates. No human in the loop. The goal: full code coverage closure, driven by LLM-powered agents orchestrated through LangGraph.
Here's what we found.
Prior Work and Where This Fits
The idea of using LLMs for hardware isn't new. ChipNeMo showed that domain-adapted LLMs can outperform GPT-4 on chip design tasks. On the verification side, ChiRAAG uses ChatGPT for iterative assertion refinement, LLM4DV demonstrated LLM-driven stimulus generation from functional coverpoints, and VerilogReader approaches coverage-centric test generation by feeding design code directly to the LLM. More recently, multi-agent systems like MAGE tackle RTL code generation by decomposing the task across specialized agents, and Saarthi applies agentic AI to formal verification with end-to-end property generation and proving.
These works demonstrate feasibility. But they leave gaps. Most don't tackle automated coverage closure from specifications, which is how verification engineers actually work. None systematically analyze where inference-time tokens go during agentic verification, or classify why certain coverage holes remain stubbornly unclosed. And very few evaluate on designs large enough to represent real unit-level verification.
The Architecture
CovAgent implements a ReAct (Reasoning + Acting) loop as a LangGraph state graph. The agent has access to purpose-built verification tools: file operations for reading specs and writing testbenches, simulator tools that compile and run designs through QuestaSim, and analysis tools that parse coverage databases to identify exactly which lines remain uncovered.
The workflow mirrors what a verification engineer does on day one. The agent reads the specification. It generates a testbench with constrained random stimulus. It compiles, simulates across multiple random seeds, merges coverage, and examines what's missing. The annotated source shows which lines were hit and which weren't. The agent reasons about the gaps, writes a targeted testbench, and the loop continues.
State management is filesystem-centric. Testbenches, simulation logs, coverage databases all live on disk. The LangGraph state tracks metadata only: iteration count, current coverage percentage, file paths. This keeps the agent's context window focused on reasoning rather than carrying around large artifacts. We also built a composite tool that chains write, compile, simulate, and parse into a single atomic call, cutting each iteration from 4-5 LLM round-trips to one.
Peeking into Token Utilization
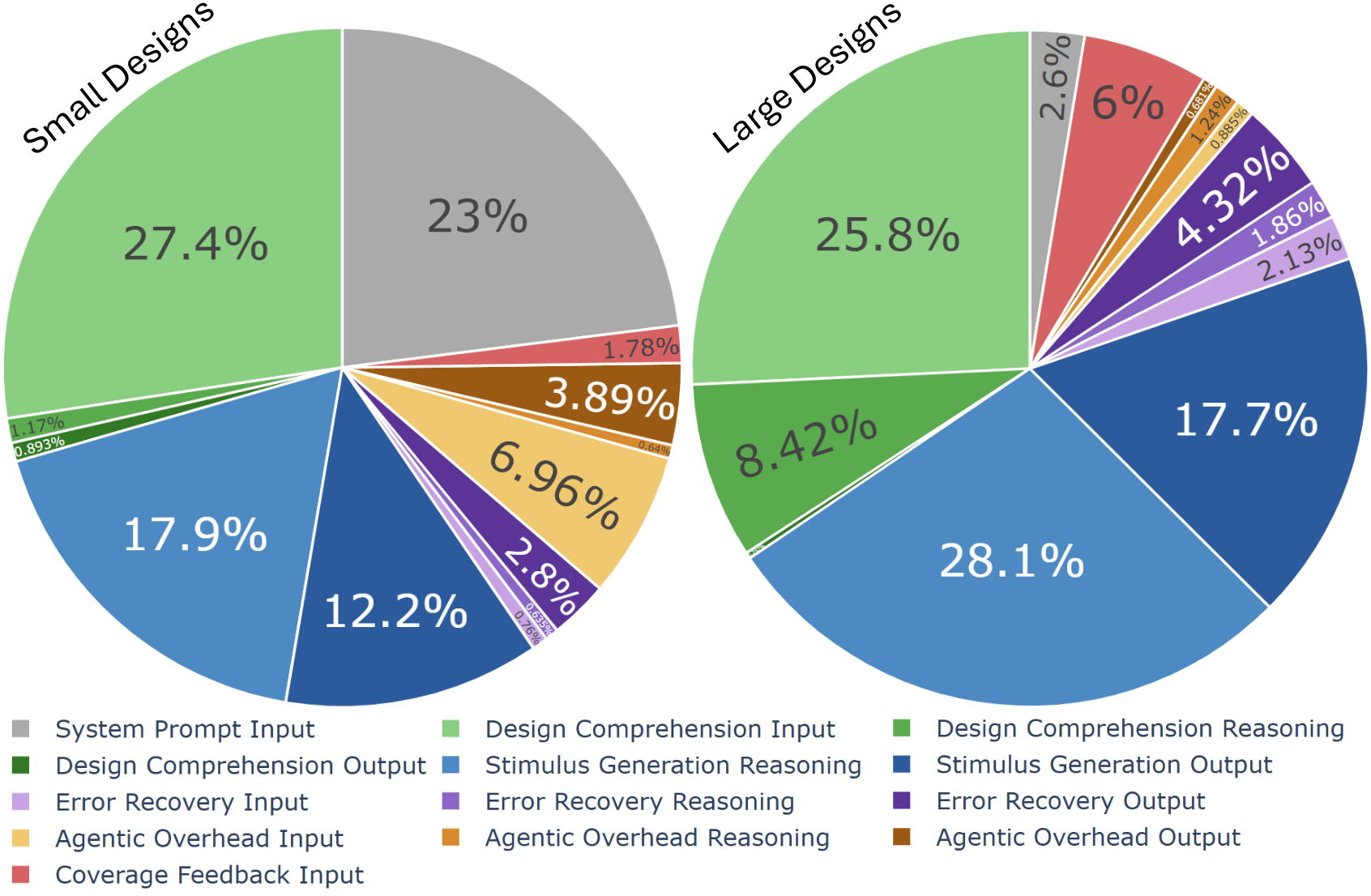
One of the more revealing parts of this work was instrumenting the system to track token allocation across six categories: system prompt, design comprehension, stimulus generation, coverage feedback, error recovery, and agentic overhead. This kind of profiling, inspired by research on scaling inference-time compute, tells you what the agent is actually spending its reasoning budget on.
The headline number: only 12-18% of tokens produce actual testbench code. Everything else goes to comprehension, reasoning, feedback processing, and infrastructure. The agent spends far more time thinking about the design than writing tests for it.
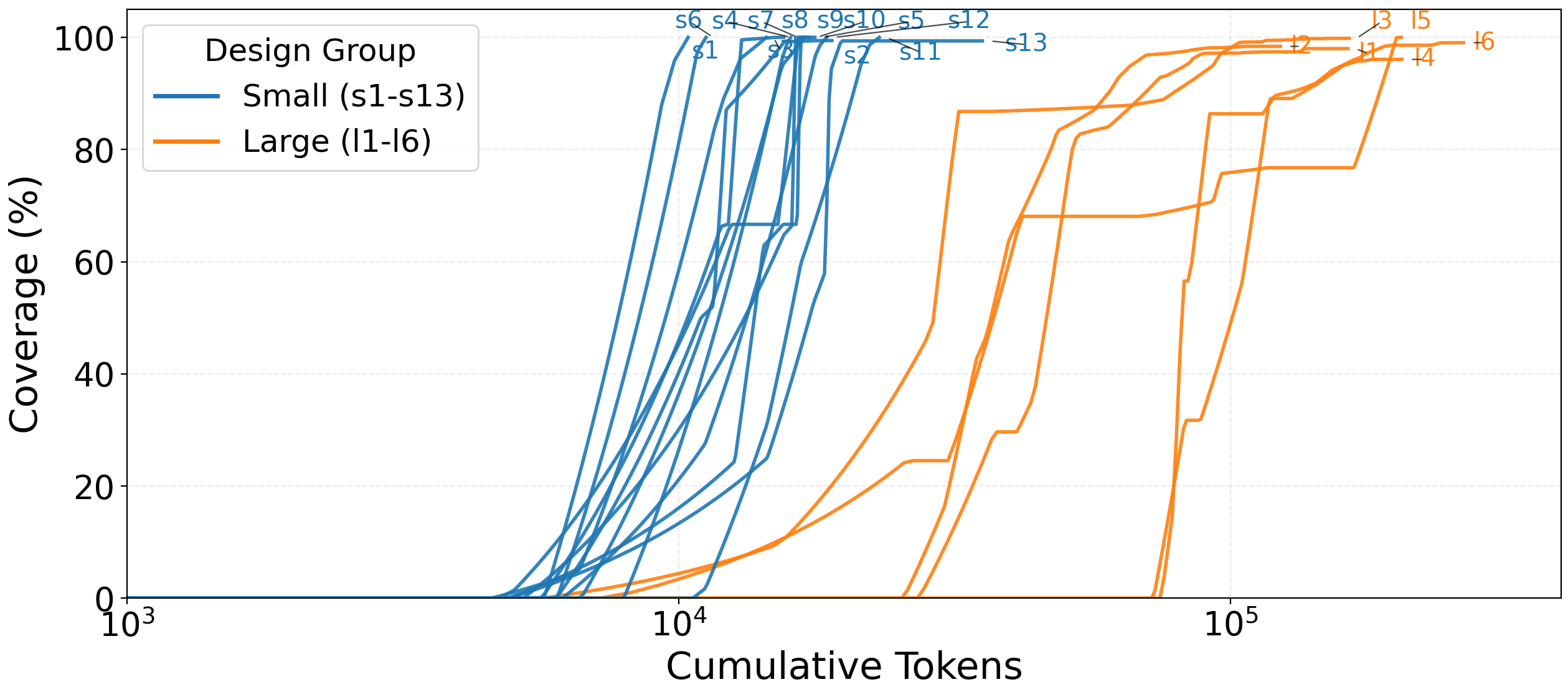
This gets worse with scale. Small designs (under ~800 lines) converge to 100% coverage within 10K-30K tokens. Large designs (2000-8500 lines) need 55K-175K tokens and plateau at 96-99%. Reasoning effort per line of code grows superlinearly. Small designs need roughly 0.1-0.3 reasoning tokens per LOC. Large designs need 4-8. Comprehension is the real bottleneck, not code generation.
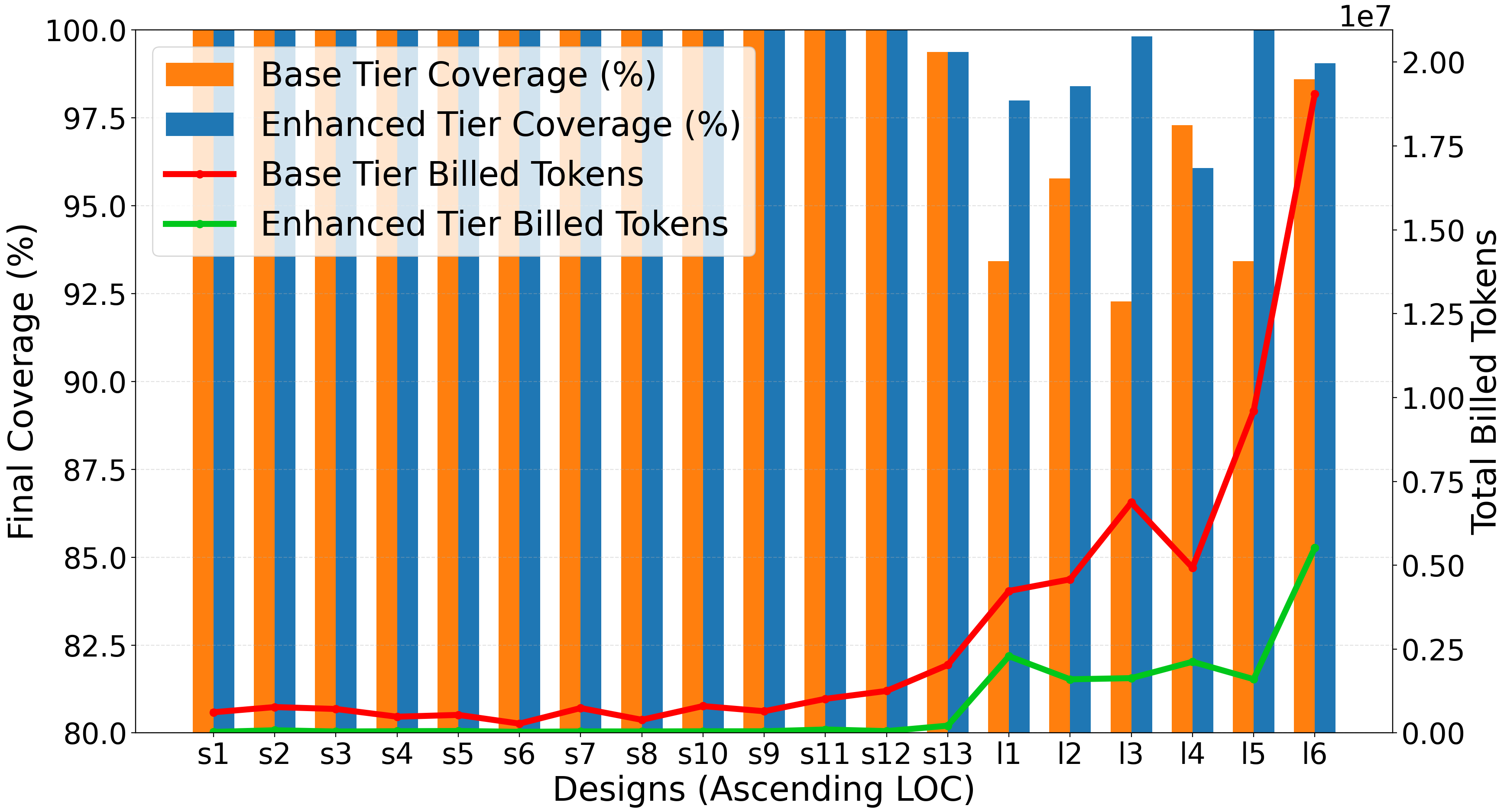
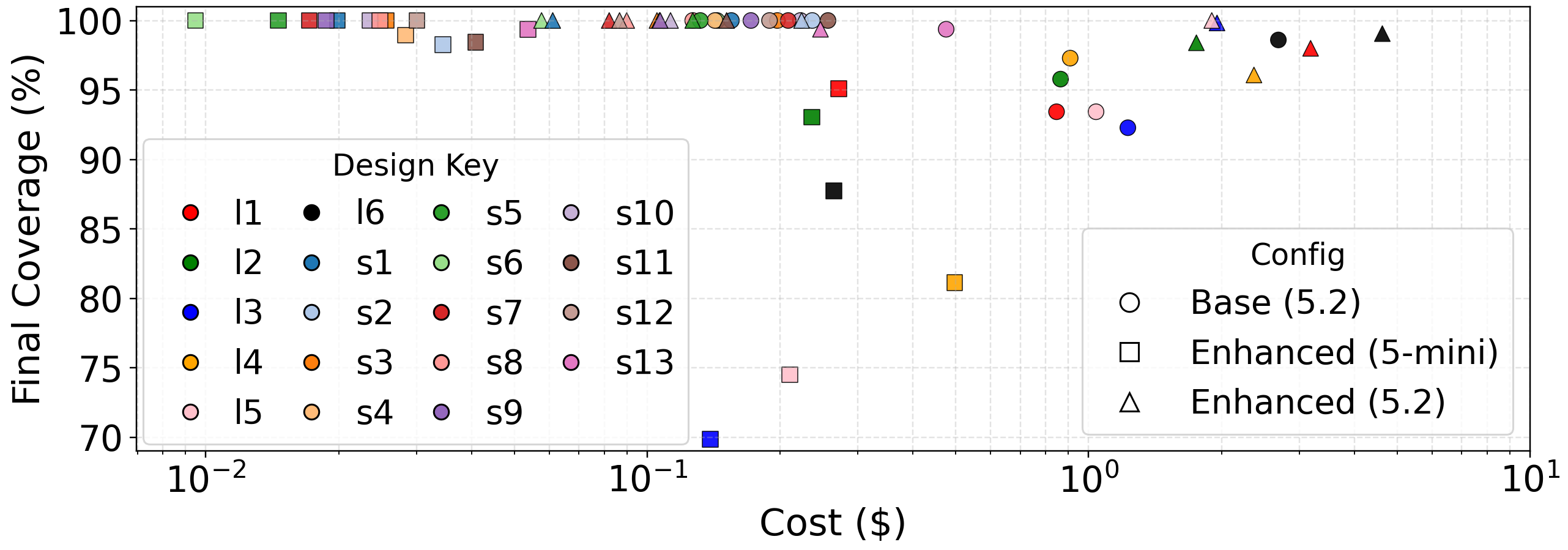
We validated this by comparing our domain-specialized LangGraph agent against a general-purpose Codex baseline using the same underlying model (GPT-5.2). The LangGraph agent achieved equal or higher coverage while using 4-13x fewer tokens. The savings came from eliminating unproductive exploration: environment setup, file discovery, ad-hoc coverage parsing. Domain specialization doesn't make the model smarter. It stops the model from wasting time. ChipAgents makes a similar argument about why domain-specialized agents will replace traditional verification workflows.
Not All Coverage Holes Are Created Equal
When coverage plateaus below 100%, the natural question is: why? We classified every residual hole across our 19 benchmark designs into a taxonomy with two categories.
Methodology-bound ceilings are holes that no amount of stimulus can close. Internal signals hardwired at the integration level. FSM defaults that exist as defensive code. Debug paths never activated in normal operation. These are exclusion candidates, not agent failures.
Reasoning frontiers are holes the agent could theoretically close but doesn't. Protocol sequencing complexity, where the agent needs to construct bus functional models for Wishbone or CAN protocols. Multi-module pipeline warmup requiring coordinated activation across deep hierarchies. Narrow timing windows demanding cycle-precise alignment.
The split is telling. On simple designs, almost all residual holes are methodology-bound. On complex designs like the Ethernet MAC or CAN controller, reasoning failures dominate. The agent correctly diagnoses what needs to happen (build a Wishbone burst model, generate bit-stuffed CAN frames) but fails to implement the solution in synthesizable SystemVerilog. The gap between diagnostic and generative capability is one of the clearest findings of this work, and it directly informs where multi-agent architectures can help.
What This Points Toward
The token allocation data and coverage hole taxonomy both point in the same direction: a single agent doing everything is not the right architecture for complex designs. This aligns with the broader push toward multi-agent systems in chip design. NVIDIA's MARCO framework uses graph-based multi-agent task solving for design automation. ChipAgents argues that structured disagreement between specialized agents, grounded by EDA tool oracles, is the path forward.
We're building toward a similar decomposition for verification. Specialized agents for design comprehension, stimulus generation, and coverage analysis, coordinated by an orchestrator. The design expert accumulates RTL knowledge persistently across a run instead of re-reading the design every iteration (addressing that superlinear comprehension cost). The stimulus generators are ephemeral workers: given a target, generate a testbench, done. Coverage merging happens at the framework level.
The reasoning frontier categories map directly to what needs improving. Protocol sequencing failures need agents with deeper domain knowledge or access to reference BFM implementations. Pipeline warmup failures need agents that can reason about multi-module coordination with a persistent understanding of the design hierarchy.
The simulator remains the oracle. Coverage is the ground truth. The agents can reason and debate, but the tools decide. That constraint is what keeps the whole system honest.




